Ausführliche Beschreibung
Ausführliche Beschreibung anzeigen
Tiefe neuronale Netze, trainiert auf Tausenden von Audioaufnahmen
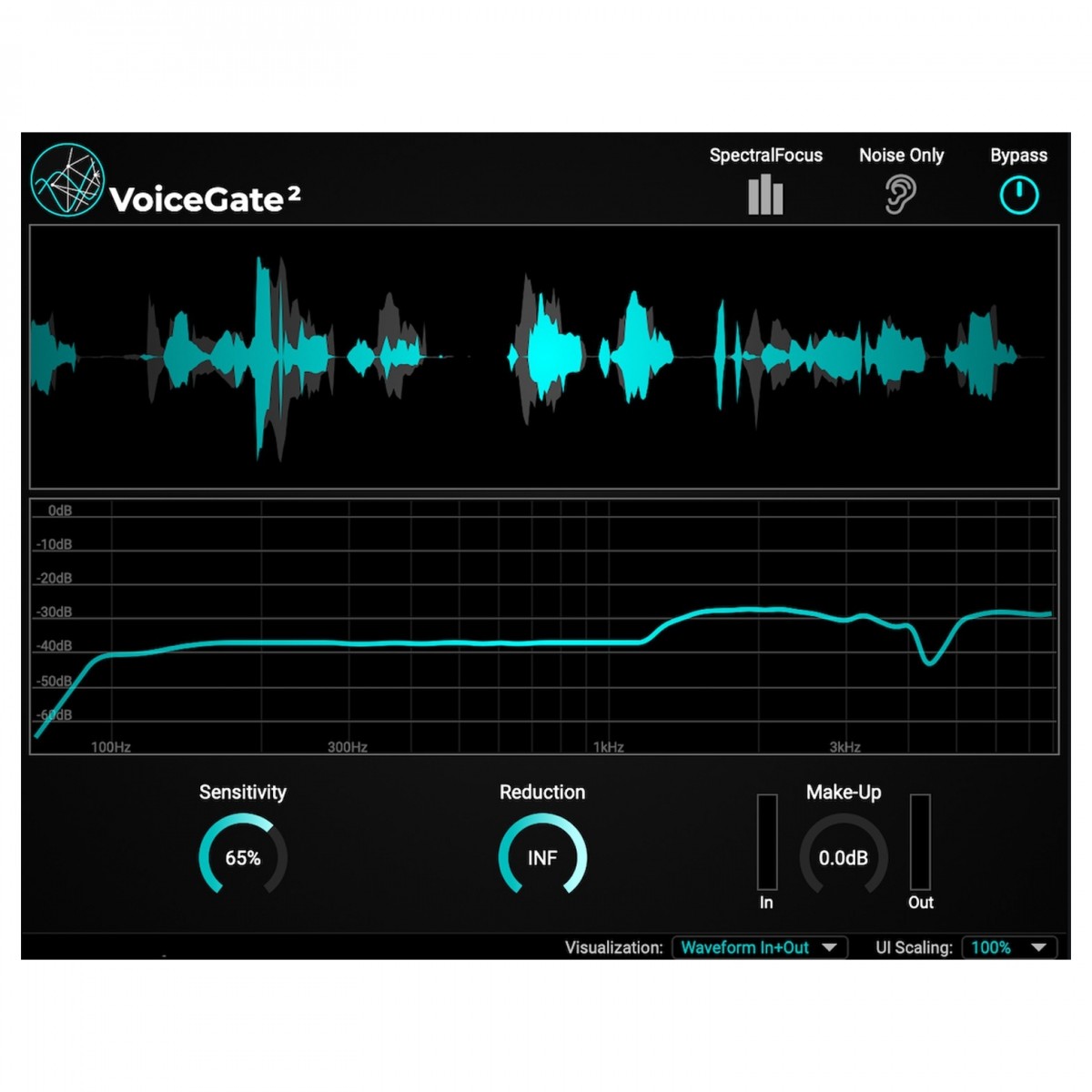
VoiceGate revolutioniert die Art und Weise, wie Sie Ihre Audioaufnahmen bereinigen. Mit seinem fortschrittlichen Algorithmus für maschinelles Lernen wurde dieses Audio-Plug-in an Tausenden von verschiedenen Aufnahmen trainiert, um die einzigartigen Merkmale menschlicher Sprache zu erkennen. Das Ergebnis? Ein leistungsfähiges Tool, das automatisch und mit bemerkenswerter Genauigkeit Sprachkomponenten von Hintergrundgeräuschen trennen kann.
Hochgradig optimiertes De-Noising für effiziente Berechnungen
Wir wissen, dass Rechenressourcen bei der Audioverarbeitung eine Einschränkung darstellen können. Deshalb wurde der VoiceGate-Algorithmus so optimiert, dass er auch auf durchschnittlichen Workstations effizient läuft, sogar in Echtzeit. Mit VoiceGate können Sie die Vorteile von tiefen neuronalen Netzen nutzen, ohne dass kostspielige Hardware-Upgrades erforderlich sind.
Automatische Anpassung für nahtlose Geräuschunterdrückung
Die automatische Anpassungsfunktion von VoiceGate bedeutet, dass Sie nicht mehr erst eine Sprachpause machen müssen, um ein Geräuschprofil zu lernen. Schließe VoiceGate einfach an, und es passt sich sofort an die Geräuschbedingungen in deiner Aufnahme an. Ganz gleich, ob es sich um Hintergrundgespräche, Raumgeräusche oder andere Störgeräusche handelt, VoiceGate bereinigt Ihr Audiomaterial mühelos und vollautomatisch.
Zeitersparnis für Ihren Arbeitsablauf
VoiceGate funktioniert direkt in Ihrer bevorzugten DAW (Digital Audio Workstation) und arbeitet in Echtzeit. VoiceGate fügt sich nahtlos in Ihren Workflow ein und ermöglicht eine effiziente Rauschunterdrückung mit nur wenigen Klicks. Sie müssen nicht mehr zwischen Anwendungen oder externen Prozessen hin- und herwechseln.
Bewertungen
"VoiceGate ist ein schnelles, leistungsfähiges Tool, das mir eine Menge Takes erspart hat, ohne meinen Workflow zu unterbrechen." - Jay Rose (CAS)
Funktionen
- Algorithmus für maschinelles Lernen, trainiert auf umfangreichen Audiodaten zur Identifizierung und Reduzierung von Störgeräuschen
- Tiefe neuronale Netze für die Unterscheidung von Sprachkomponenten und Hintergrundgeräuschen
- Optimiert für den Echtzeitbetrieb auf durchschnittlichen Workstations trotz hoher Rechenanforderungen
- Automatische Anpassung an die Geräuschbedingungen in den Aufnahmen, wodurch das manuelle Lernen von Geräuschprofilen überflüssig wird
- Echtzeit-Integration mit Ihrer bevorzugten Digital Audio Workstation (DAW) für einen nahtlosen Workflow
Spezifikationen
- Betriebssystem:
- Mac: MacOS 10.12 Sierra und höher
- Windows: Windows 7 und höher (nur 64-bit)
- Unterstützte Sample-Raten: 44.1kHz, 48kHz, 88.2khz, 96kHz, 192kHz
- Kanalformate: Mono / Stereo
- Plugin-Formate: VST3 / AU / AAX
- Zusätzliche Unterstützung: Native Apple-Silicon Unterstützung
- Produkt-Code: 1420-1003